Let's imagine you are downloading the latest memes and patiently waiting for the download to complete. The meme, of course, is fire, so you send a link to your friends. They grab the file from your phone and then start sharing with their friends. At this point the meme lives on a couple dozen devices so when someone new gets the link they end up connecting to several other people and getting a few bits from each of them making the download almost snapshot.
ContentsWhat is the Interplanetary File System?Why is it great?How It Works:The Short VersionHow It Works:The Technical VersionContent Addressing:What, Not WhereMerkle-DAGs:Everything Has A CID, And They All Are ConnectedDistributed Hash Tables:How IPFS Locates ContentIPFS Is Cool, But Will It Take Off?Thanks to the Interplanetary File System, the very real and surprisingly easy-to-use system just might be our key to a faster, more democratic internet. As described above, the basic idea is that user devices store, index, and serve data that currently resides on centralized servers. If that sounds a bit like cryptocurrency, you're not wrong – the man behind the project, Juan Benet, described IPFS as "In a sense, doing to websites… what Bitcoin did to money.“
If you know how BitTorrent or any other P2P (Peer-to-Peer) technology works, you are the best way to understand what IPFS does. It sends files (including the HTML, CSS, and JavaScript files that make up most websites) and chunks of files between users' devices, much like torrenting a piece of public domain music totally legally. /P> 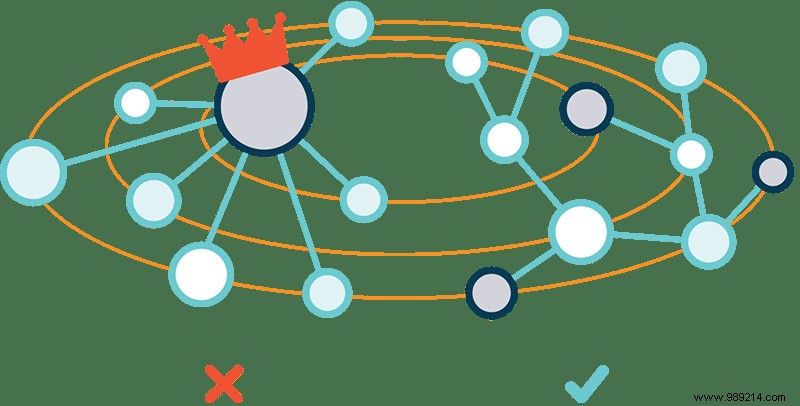

Everyone can use the IPFS network now, because it has become very user-friendly. Here's what happens:

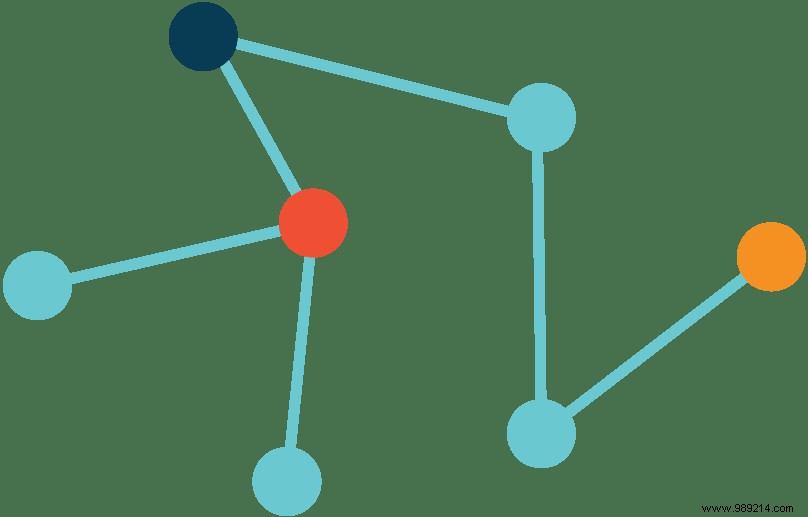
Even simpler translation:IPFS assigns a name to each piece of data, lists where that data is located at any given time, and helps devices send data directly to each other.
There are three main things that make IPFS work:content addressing gives data identity, Merkle-DAGs give it structure, and distributed hash tables tell you where to find it.
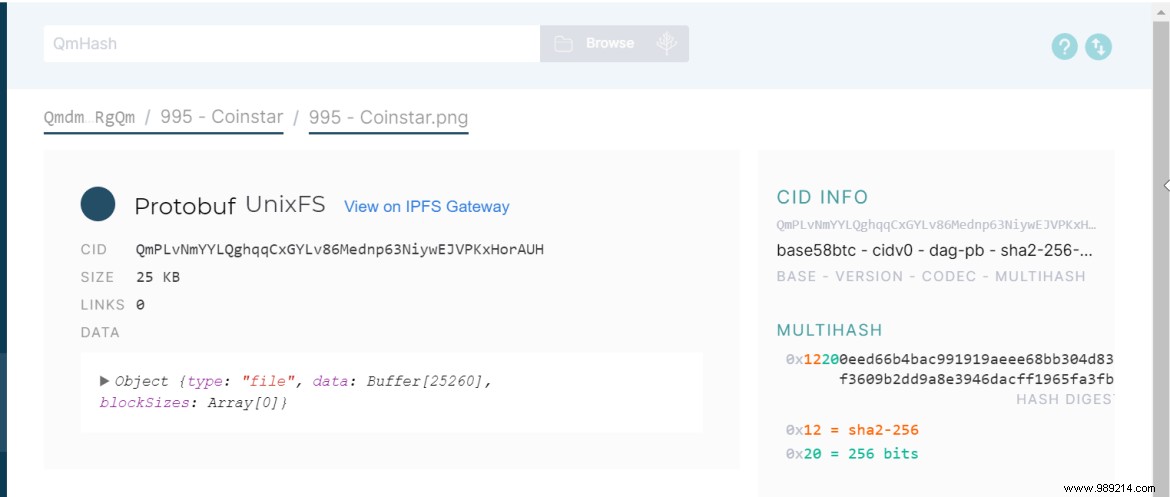
Most of our current content has location-based addresses (C:/Users/Username/Documents, 192.124.249.3, etc.) that tell us where to go to find the data. This won't really work in a decentralized system, as content can be stored just about anywhere, so systems like IPFS and BitTorrent use "content addressing" instead.
A content addressing system works by running a piece of data through an algorithm that assigns it a unique identifier, or hash. Each identical copy of the file will have the same ID, which means that when IPFS searches for it, it can find all instances stored on the network.
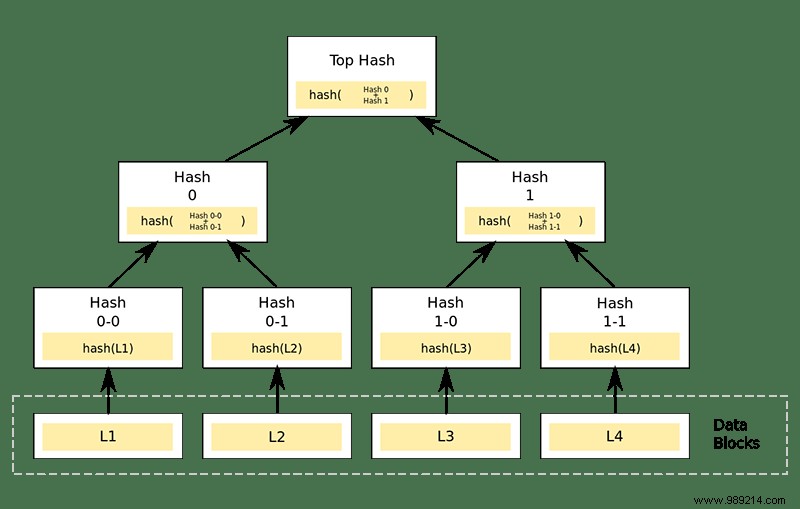
As much as it sounds like a German political party, a Merkle-DAG (directed acyclic graph) is actually a way to organize data. In this system, each piece of data has its own content ID (CID):folders, files, blocks of data within files – everything. This means that files can be split into different parts, authenticated and reassembled.
The IPFS documentation describes it as a "bottom-out turtle scenario" because everything can be broken down into a collection of data identifiable by a CID. A folder's CID will direct you to a collection of file and folder CIDs, whose CIDs will then direct you to other CIDs that represent other content items, also with their own CIDs. Any changes to a file will cause its hash and folder hash to change.
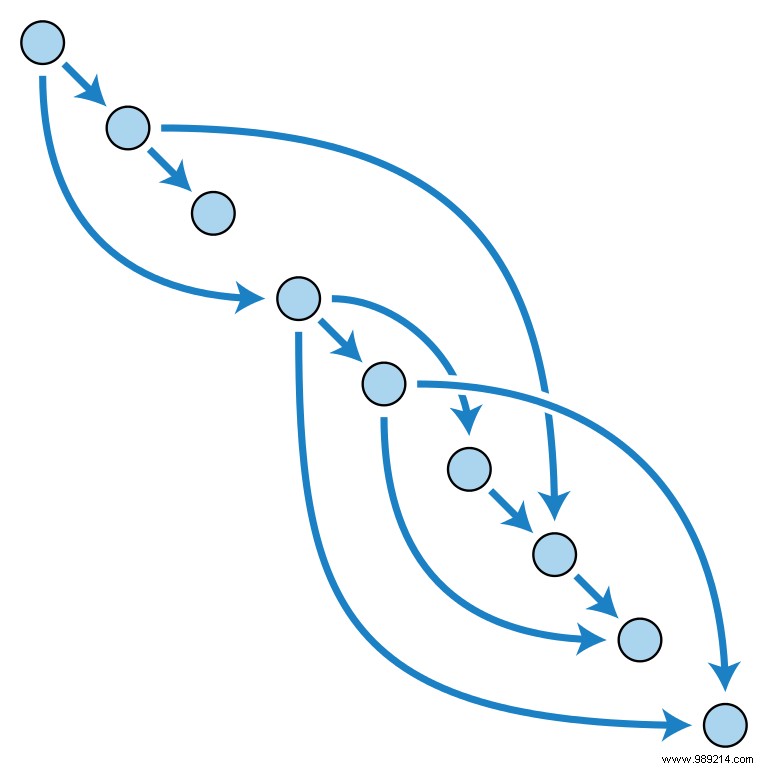
The data doesn't really live here - it just tells you where to find it and how all the pieces should fit together once you have them. The Merkle-DAG is essentially what gives all of these identifiers a structure, much like your computer's file system.

So how can we find who has the data we want? Basically, there's a large database that matches content IDs with the locations of computers that host that content, and the database itself is shared among everyone on the network. When you request a piece of content represented by a CID, your computer searches for the CID until it finds a list of people who have it. Your computer then connects to these people, downloads the items you need, and puts them together. This is the distributed hash table – basically a big list of who has what.
IPFS started in 2015 and has grown rapidly ever since. Dozens of applications and sites have been built on it, such as a blockchain file storage system (Filecoin), and a GeoCities replacement (Neocities). It's managed to strike the right mix of decentralization and user-friendliness, which is probably why it's become a go-to for projects looking to decentralize, like Sociall (a decentralized social network) and Courageous.
>Cloudflare's IPFS Gateway has been a great success, and using the network is getting easier and easier; All you have to do is download a program and install a browser extension. Of course, there's some debate over whether this really is the best solution - it's far from the only project with the same vision - but it shows no signs of slowing down. Although it won't completely replace HTTP, it certainly looks like it will be part of the next version of the Internet.
Image credits:Directed Acyclic Graph, Hash Tree, IPFS